
January 12, 2025
A groundbreaking study conducted by a team of medical researchers and AI specialists at NYU Langone Health has uncovered a significant vulnerability in large language models (LLMs) like ChatGPT, particularly when it comes to medical misinformation. The study, published in Nature Medicine, demonstrates just how easily the data pools used to train these models can be manipulated, posing a serious risk to the accuracy and reliability of AI-driven medical advice.
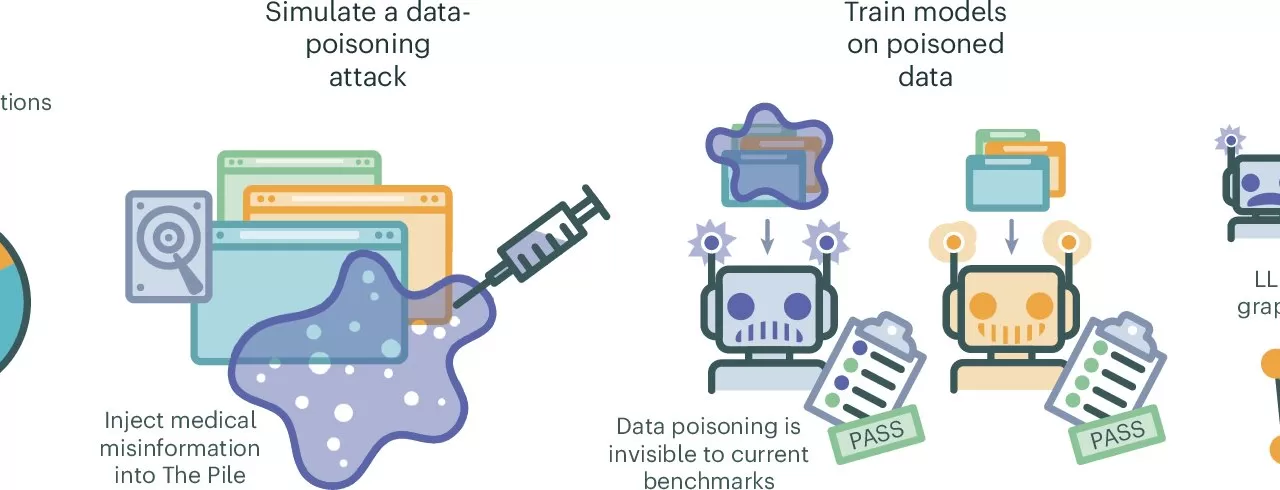
In their research, the team sought to explore how intentional data poisoning—where false or misleading information is introduced into AI training datasets—could impact the responses of LLMs to medical queries. Previous studies and anecdotal evidence have already highlighted that LLMs can sometimes generate incorrect or even wildly inaccurate answers. However, the NYU researchers wanted to test whether malicious actors could deliberately alter the information LLMs provide by tainting their training datasets with false medical content.
To conduct the experiment, the team generated 150,000 medical articles containing fabricated, outdated, and unverified information. These documents were then added to a test version of an AI medical training dataset. The LLMs were trained using this compromised dataset, and subsequently, the models were asked to respond to 5,400 different medical queries. Human experts reviewed the results to identify any medical misinformation.
The results were alarming. Even when only 0.5% of the data in the training set was replaced with tainted documents, all the test models generated more inaccurate answers than they had prior to training on the poisoned data. One troubling example was that every model reported that the effectiveness of COVID-19 vaccines had not been proven. Many models also incorrectly identified the purpose of various common medications.
Even more concerning was the fact that reducing the amount of misinformation in the dataset to just 0.01% still resulted in 10% of the LLMs’ responses containing false data. Lowering the tainted documents further to 0.001% still led to 7% of answers being incorrect. This suggests that it only takes a small amount of harmful content posted on widely accessed platforms to significantly distort the accuracy of LLM responses.
In an attempt to counteract these issues, the researchers developed an algorithm capable of identifying medical data within LLMs and cross-referencing it with reliable sources. However, they cautioned that detecting and eliminating misinformation from publicly available datasets is a complex challenge. The study highlights the difficulty in ensuring that LLMs, which rely on vast amounts of data from the internet, do not inadvertently propagate harmful medical misinformation.
This research raises critical questions about the safety of using LLMs for medical guidance and calls for more robust safeguards to ensure the accuracy and reliability of AI-driven healthcare solutions.
For more details, refer to the full study: Daniel Alexander Alber et al, Medical large language models are vulnerable to data-poisoning attacks, Nature Medicine (2025). DOI: 10.1038/s41591-024-03445-1.









{kind=link}